research Research programme Module 3
Module 3

We maintain that the bottleneck in seismic history match lies in the lack of match between the predicted and observed seismic data. This creates complex artefacts in the solution space, that can bias the parameter estimates. In Phase VIII we investigated the errors and uncertainties behind this mismatch, starting from the choices made during pre-stack processing and moving on to the model errors in sim2seis. These revealed many items that can be changed, such as overburden and underburden modelling, specification of the pressure sensitivity and saturation heterogeneity, and basic calibration of key reservoir events. The numbers of unassigned physical variables in the sim2seis can become large, and to achieve an adequate ‘like-for-like’ match to the observations we require ‘a history match within a history match’, in essence a calibration step prior to the proper SHM in which we map onto the 3D and 4D data. Building on these studies and philosophy, we wish to move towards our final objective of designing an ideal SHM that truly reflects the desired model parameters to be estimated for field production management. We do this by continuing to study the errors and uncertainties to conclusion, and then implement our desired scheme. Finally, as a separate theme we start to explore with the use of data donated from sponsors the impact of different timings of seismic surveys on our ability to update the simulation model, within the particular context of fast-moving mechanisms such as WAG, CO2 injection or geomechanical effects. In this work we continue to use our toolbox of HM methods, MOPHIiM, established by Romain Chassagne and Tony Hallam (previously of ETLP). With the evolution of ETLP’s v 2.0 (Meta-heuristic optimisation platform for history matching, MOPHIiM) our tool for implementing seismic history matching over Phase VII, our ability to implement a coherent SHM workflow over Phase VIII and into Phase IX has improved. The software enabled us to link data to simulations via a specific objective function that can be optimised using several algorithms such as SHADE, differential evolution, CMA-ES and particle swarm optimisation. The code is written in Python and is in an easy-to-use plugin in, plugout environment. This has provided new students and staff with a flexible environment to quickly assess new ways to create model update.
Errors and uncertainty
ETLP recognises that there is a large list of disparate errors (fluid flow model realism, seismic modelling, data processing, wavelet, PEM, overburden/underburden, scale-related, etc..) that contribute to the final match between the predicted and the observed 4D seismic data (Portaluri and MacBeth 2022). Many of these errors arise as the simulation model we receive has deviated from the original 3D seismic information used to build it during its journey of construction using various datasets, and also because of the limitation of the scale of the grid cells and model dimensions. Most of these errors are ignored in the popular practice of comparison using a mathematical objective function, for which an extensive array of literature has emerged. In Phase VIII we explored this topic in two ways:
(a) model-driven error – i.e. the errors that arise in modelling for sim2seis. These include, but are not limited to, assignment of overburden and underburden properties (see Figure 13), choice of wavelet, scaling, wave propagator, PEM stress sensitivity, saturation heterogeneity, stochastic variation, and geological description. These effects have been examined to determine their sensitivity on the output seismic, and ways of improving these by fitting to 3D data are considered.
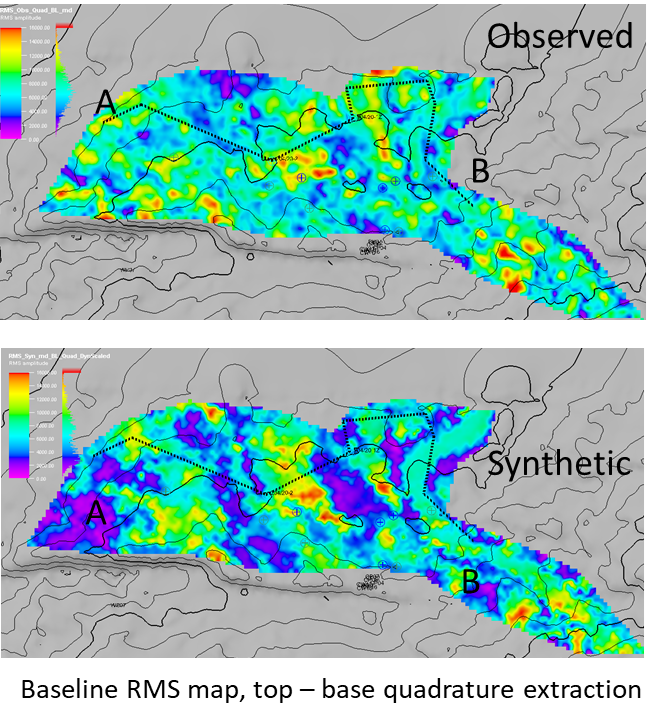
(b) Data-driven: choices made during pre-stack processing have been shown to affect the 4D amplitudes and to some extent the time-shifts (Hatab and MacBeth 2021, 2022, 2023; ).
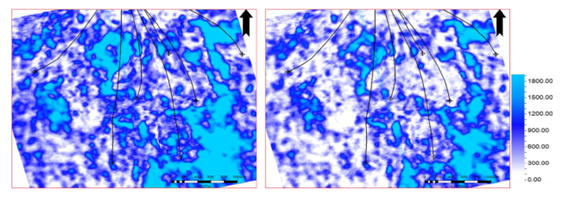
To date these errors (contributing to both a bias and uncertainty) have not been considered. We have shown that by taking these errors into account in the seismic history match, a wider and different range of plausible solutions is obtained (Figure 15). This then allows us to propagate seismic error deeper into the workflow, and to translate this into realistic model parameter errors. Unfortunately, the evaluation of error from pre-stack processing is time-consuming and labour intensive. We plan to take these studies further by applying to several datasets, and finding ways of quick and efficient ways of capturing data error (such as experimental design).
The following will be considered:
The misfit definition:
- Continuation of investigation on model error to finalise and develop a method for creating an optimal fit to 3D and 4D observed data,
- A complete seismic history match using the scheme in the previous point,
- A scheme to speed up data error evaluation,
- Evaluation of error on simulation model estimates from data error,
- The value of time-shifts in SHM and error appraisal.
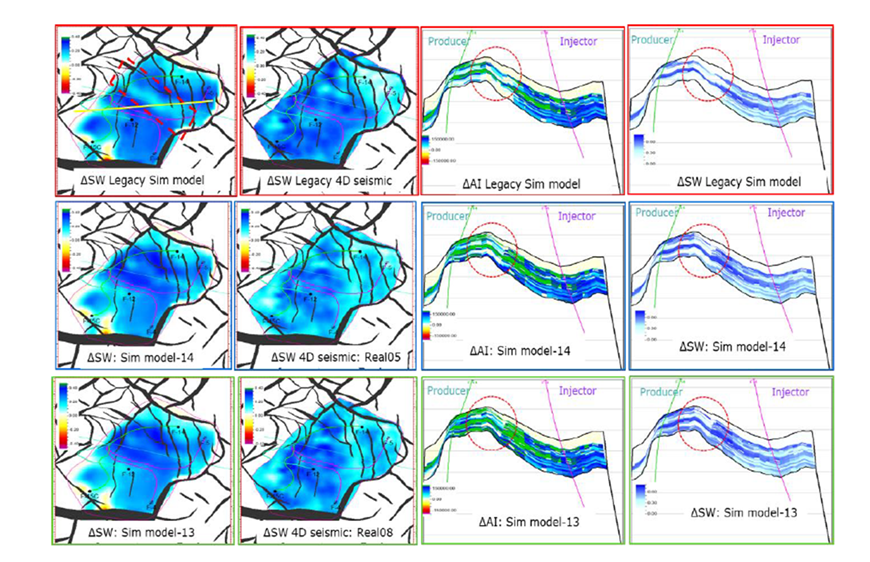
Seismic-model reconciliation
We recognise that during the standard sequential industry workflow, the information content in the simulation model drifts away from the seismic information initially used in the building procedure. This is because data from other disciplines have been included, and the model is smoothed and gridded to suit the purposes of fluid flow simulation. Thresholds have been applied during the model building to assign properties to the grid. As such we do not actually expect the sim2seis procedure to output seismic volumes that match those of the observations. This mismatch can be tolerated at the field-scale and occasionally at the well-scale for the purposes of manual direct updating but cannot be tolerated if we wish to carry out a true SHM when a one-for-one quantitative match is necessary, as otherwise artefacts and biases will be present in the solution space. The errors and uncertainty analysis of the previous sub-module helps towards reconciling both the observations and the sim2seis predictions. However, a mis-match will still remain that may need careful re-building of the simulation model to honour the seismic observations, whilst also maintaining the same degree of match to the production data, and also petrophysical and geological credibility. This may require a complete and careful rebuild from the geological model, or the use of some other paradigm in model building. As this process will probably be time-consuming, we will also look for ways to speed up this procedure and close the small loop between the geophysicist and reservoir engineer.
The following will be considered:
- Simulation model build to honour 3D and 4D data,
- Preservation of history match,
- Reconciliation towards a more quantitative seismic history match,
- Use of machine learning,
- Refinements of tools for fast turnaround/best procedure and workflows.
Frequency and value
Whether assessing CO2 injection programmes or monitoring producing hydrocarbon reservoirs, the returned value is intimately connected with the survey frequency, survey types, cost and economic model of the project. To address what acquisition strategy supports the optimal strategy with minimum cost is a complex equation that needs further investigation. This sub-module investigates this issue in the context of our hydrocarbon production examples using our datasets donated by sponsors as a template. In Module 4 we discuss this question from the point of view of CO2 injection. Questions to ask are: What is the optimal frequency? What is the minimum expected cost from a set optimal strategy? How should we design our seismic monitoring to maximise value and minimise cost? By investigating a diversity of fields in different countries, we can explore a number of possible options that contribute to an optimal strategy. We use as a framework a Bayesian network and information theory, and a decision-based system of value of information analysis.
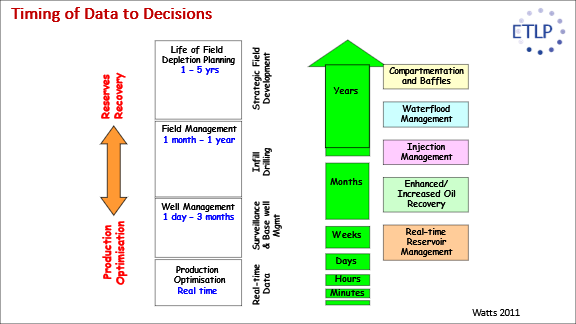
Previous ETLP work has evaluated 4D seismic surveys over a range of acquisitions, from PRMs with a frequency of 3 to 4 months to more routine surveys that are one to several years apart. In an exceptional dataset ETLP studied the SeisMovie data from Peace River at a frequency of one survey per day for 700 days. The mechanism was steam injection into heavy oil. Lopez et al. (2016) defined the optimal monitoring frequency for this dataset to be 3 months after evaluating all the costs, value, and decision-making steps in an operational setting. We know that as an industry we are acquiring more 4D seismic surveys, more frequently and believe that the proper choice of when to shoot may well be important in the long term (within the bounds of practical considerations like weather windows). The study will be based on several well-founded, history matched simulation models. An important aspect to include is the role of SHM in the decision making. We should also respect the timescale of each physical mechanism in the reservoir (see Figure 16). We should address whether the monitoring of these reservoir parameters is worth the extra cost? How to justify the costs with added benefits from the flow of information. This question may not be easy to answer when the benefits are not easy to measure, particularly if they are purely enhanced decision making. For example: if the added information leads to the same development of drilling plans, then improved understanding may be worthless. The information itself does not have any value. The value is in more informed development plans, more efficient wells, or enhanced management of the reservoir.
The importance of applying to appropriate field datasets: Field datasets form the backbone of ETLP studies. The simulation model in particular is key to understanding the fluid flow and pressure variations during production and is essential for closing the loop with the 4D seismic data. We now have access to a wide range of simulation models which our reservoir engineering-polarised students will use as a starting point for their research studies. We recognise that a reliable well-history matched simulation model is also required to provide any chance of success in seismic history matching. Given our current datasets, in this model we will continue to build case studies applying existing SHM and closing the loop techniques to different datasets and settings.
The importance of search space – a key to implementing the three topics above will be efficient search of solution space, and a metric for evaluating the complexity of this space. This has been developed in ETLP in parallel to the initiatives above (Mitchell and Chassagne 2022, 2023). As this research develops it will add to the existing MOPHIiM package and provide a backbone for implementing the intended programme of work.
In all of the above, we seek to produce as many case studies as possible to fine-tune our generic approach and to mature our understanding of what is possible in this vital last stage of the 4D workflow journey.